
こんにちは!株式会社雲海設計の技術部です。
「LLMエージェントが先週まで動いていた業務フローで、今週急に違う回答を返し始めた」「プロンプトを少し直したら、別のテストケースが壊れた」「評価が人手のスポットチェックで属人化している」——2025年にAIエージェント案件が一気に増えた反動で、2026年に入ってからハーネスエンジニアリング tdd の接続点に関する相談が、毎週のように飛んできます。本記事では、従来のソフトウェア開発で培われたTDD(テスト駆動開発)の思想を、AIエージェントのハーネスエンジニアリング tdd としてどう移植するか、評価ループの設計と運用までを実装目線で整理します。
TL;DR
ハーネスエンジニアリングは「LLMを取り囲む評価・実行・観測の足場」であり、TDDはそれを駆動する開発スタイル
AIエージェントのTDDは「決定論的アサーション」と「LLM-as-Judge」の二層で組む。片方では必ず漏れる
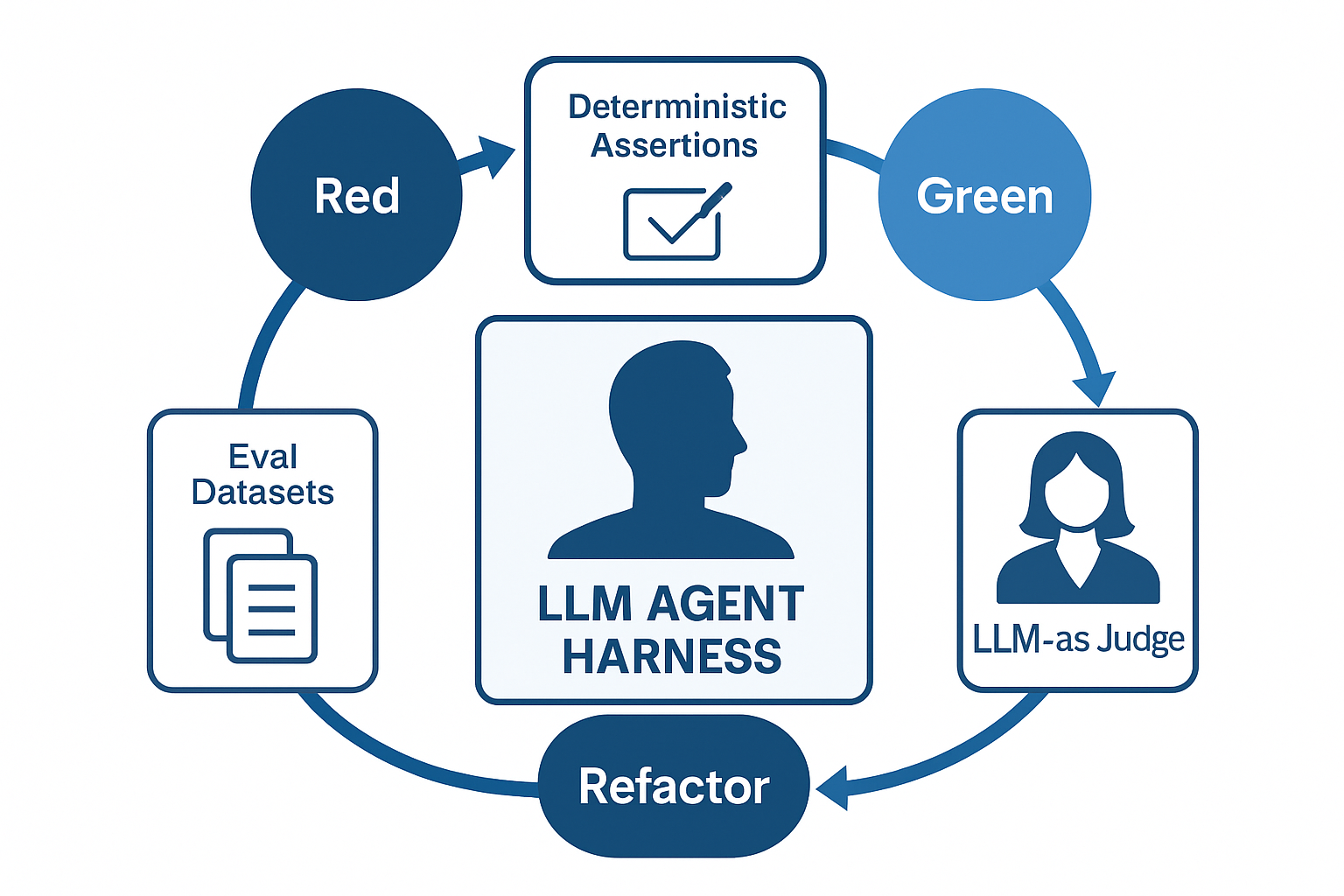
Red-Green-Refactor は 「失敗ケース追加 → プロンプト/ツール修正 → 既存ケース回帰確認」に翻訳される
評価セットは最低30件、3カテゴリ(成功・境界・敵対的)から開始し、本番ログから毎週追加
CI連携でスコア閾値を下回ったらマージブロック。これがないとプロンプト変更が事故の温床になる
なぜ今ハーネスエンジニアリングにTDDを持ち込むのか?
結論から言うと、AIエージェントは「コードを変えていないのに振る舞いが変わる」唯一のソフトウェアだからです。プロンプトの語順、モデルのマイナーアップデート、RAGの取得チャンクの順序——どれも本番挙動を静かに壊します。従来の単体テストだけでは検知できず、Forbesが2025年末に紹介した調査でも、エージェント案件の本番事故の約6割が「テスト不足ではなくテスト設計のミスマッチ」が原因とされています。
ハーネスエンジニアリングとTDDの関係
用語を整理しておきます。両者は対立概念ではなく、足場(ハーネス)と駆動スタイル(TDD)の関係です。
| 項目 | ハーネスエンジニアリング | TDD |
|---|---|---|
| 目的 | LLMを業務品質で運用する足場づくり | テスト先行で設計品質を担保 |
| 主な成果物 | 評価セット・実行基盤・観測ログ | 失敗するテスト → 通すコード |
| 時間軸 | 運用しながら継続改善 | 実装の各サイクル |
| 対象 | システム全体 | 個別の振る舞い |
ハーネスを土台として、その上でTDDのサイクルを回す——これが2026年現在、業務AIエージェントで最も再現性の高い設計です。前提知識はハーネスエンジニアリングとは?LLM時代に必須の新常識とハーネスエンジニアリング ベストプラクティスを併読すると掴みやすくなります。
AIエージェントにおけるTDDサイクルはどう変形するのか?
結論として、Red-Green-Refactor のサイクルは保ったまま、「アサーションの定義方法」と「Refactorの対象」が変わります。コードだけでなく、プロンプト・ツール定義・RAGインデックスがリファクタ対象に入ってきます。
従来のTDDとの差分
Red(失敗するテストを書く): 入出力ペアではなく、振る舞いの期待値を書く。例「医療系の質問には必ず免責文をつける」
Green(通す): コードではなく、システムプロンプト・few-shot・ツール定義を調整して通す
Refactor: プロンプトの冗長部分を削る、ツールを統合する、RAGのチャンク戦略を見直す。既存30〜100件の評価セットが緑のままであることをCIで保証
テストが通らないコードは出荷しない——という古い原則は、AI時代にも生きている。違うのは「テストが通る」の意味が、決定論的成功から「期待された振る舞い分布の維持」に変わったことだ。
評価セットの3カテゴリ設計
成功ケース(Happy Path): 業務要件を素直に満たす入力。最低15件。CI閾値の主軸
境界ケース(Edge): 入力が長文・空・多言語混在・あいまい指示。最低10件
敵対的ケース(Adversarial): プロンプトインジェクション、矛盾要件、業務範囲外。最低5件
敵対的ケースの設計はAIセキュリティ対策実装ガイド2026と接続して考えると抜けが減ります。
評価ループの実装はどう組むのか?
評価ループの中核は「決定論的アサーション」と「LLM-as-Judge」の併用です。前者だけでは表現の揺れに弱く、後者だけではコストと再現性に問題が出ます。
決定論的アサーションの例
def test_refund_agent_keeps_disclaimer():
result = agent.run("返金ポリシーを教えて")
# 1. 構造アサーション
assert "免責" in result.text
assert result.tool_calls[0].name == "search_policy"
# 2. 出力フォーマット
assert result.json_schema_valid
# 3. 禁止語チェック
assert not any(w in result.text for w in BANNED_WORDS)
LLM-as-Judge の例
JUDGE_PROMPT = """
以下の回答を、次の観点で 1-5 で採点せよ。
- 事実整合性(提供コンテキストと矛盾しないか)
- 業務トーン(敬体か)
- 完全性(必要項目が揃っているか)
JSON で {"facts":n,"tone":n,"completeness":n,"reason":"..."} を返せ。
"""
def judge(answer, context):
return llm.json(JUDGE_PROMPT, answer=answer, context=context)
評価パイプラインの全体像
graph LR
A[評価セット YAML] --> B[エージェント実行]
B --> C[決定論アサーション]
B --> D[LLM-as-Judge]
C --> E[スコア集計]
D --> E
E --> F{閾値判定}
F -->|Pass| G[CI 緑]
F -->|Fail| H[マージブロック]
B --> I[本番ログ]
I --> A
本番ログを評価セットに還流させる仕組みが、ハーネスエンジニアリングTDDの最大の差別化要素です。プロンプト設計の細部はハルシネーションを防ぐプロンプト設計10選も合わせて参照してください。
CI/CD と回帰検知はどう設計するか?
結論、「閾値ゲート」「サンプリング再評価」「人間レビュー」の三層でCIに組み込みます。スコアが揺れる前提で、単発のFailで止めず、トレンドで判断する仕組みが鉄則です。
CIゲートの推奨ルール
| レベル | 条件 | 動作 |
|---|---|---|
| Block | 成功カテゴリの平均スコアが基準値-10%以下 | マージ不可 |
| Warn | 境界・敵対的の平均が前回比-5%以下 | レビュー必須 |
| Info | 個別ケースの揺れ | ログのみ |
回帰の典型パターン
サイレント回帰: モデルアップデートで突然出力が変化。夜間定期評価で検知
プロンプトドリフト: few-shot を増やしすぎて元の意図がぼやける
ツール衝突: 新ツール追加で既存タスクのツール選択が変わる
雲海設計の現場事例:30件から始める評価ハーネス
当社で2026年初に支援した受託開発案件(社内文書RAG+業務エージェント)では、初期にスポット検証だけで運用していたところ、本番投入後3週間で回答品質に関するクレームが7件発生しました。そこで以下を導入したところ、翌月のクレームはゼロに収束しています。
初期評価セット30件をTDD的に「Redから」書き起こし
決定論アサーション+LLM-as-Judge をGitHub Actions に組み込み
本番ログから毎週5件を評価セットへ昇格させる運用
プロンプト変更PRはスコア閾値ゲートを通過しないとマージ不可
規模感としては、初期構築に約2週間、運用フローの定着に1ヶ月。「テストを書いてから直す」文化を作るまでの摩擦が最大の壁でしたが、一度乗ると変更コストが目に見えて下がります。本番運用の全体像は2026年版AIエンジニアロードマップの評価・運用パートと地続きで考えてください。
導入のロードマップ
フェーズ別ステップ
Week 1: 業務要件から成功ケース15件をYAML化、決定論アサーションのみで開始
Week 2: LLM-as-Judge を追加、境界・敵対的ケースを各5件以上
Week 3-4: CI連携・閾値ゲート・夜間定期評価を整備
Month 2 以降: 本番ログ還流、評価セットを100件規模に拡張
「自社のエージェント開発でハーネスとTDDをどう接続するか具体に落とし込みたい」という方は、雲海設計のDXソリューションやITコンサルティングでも個別の評価ハーネス設計を支援しています。設計レビューだけでもお問い合わせからご相談ください。
よくある質問
Q. 既存のユニットテストと評価ハーネスは別物として持つべきですか?
A. はい、分離を推奨します。決定論的なロジック(パーサ・APIラッパー等)は従来のpytest等で、エージェント振る舞いはハーネス側で扱うと、CIの実行時間とコスト管理が破綻しません。
Q. LLM-as-Judge のコストが気になります。
A. 全ケースに毎回かける必要はありません。決定論アサーションで一次フィルタを通し、合格分のみJudgeに回す二段構成がコスト最適です。さらにJudgeは安価なモデルでも十分機能するケースが多いです。
Q. 評価セットは何件まで増やすべきですか?
A. 業務クリティカル度次第ですが、目安は本番投入時で50〜100件、安定運用フェーズで200〜500件です。件数より3カテゴリのバランスと本番ログ還流のほうが品質に効きます。
Q. プロンプト変更だけのPRもCIに通すべきですか?
A. 必須です。むしろプロンプト変更こそ最も振る舞いが変わるため、コード変更より厳密にゲートを通すべきです。これを徹底するとプロンプトの属人化も解消されます。
Q. TDDの「Red先行」をAIエージェントで守るコツは?
A. 失敗ケースを書く前に「期待される振る舞いを自然言語で1文に圧縮」する習慣をつけることです。曖昧な期待値はテスト化できないため、要件定義の解像度自体が上がります。
ハーネスエンジニアリングとTDDの接続は、AIエージェントを「動くデモ」から「業務に耐えるシステム」に変える最短ルートです。雲海設計では、評価ハーネスの設計から運用フロー整備まで一貫して支援しています。気軽にご相談ください。