
こんにちは!株式会社雲海設計の技術部です。
「GPT-4oやGPT-5系で業務エージェントを組んだが、品質が安定しない」「OpenAI Evalsを触ってはみたが、業務指標に落とし込めない」「ClaudeのハーネスをGPTに移植したいが、何を変えれば良いか分からない」——2026年5月現在、ハーネスエンジニアリング openaiに関する相談が、技術部に毎週のように寄せられています。本記事では、ハーネスエンジニアリング openaiの実装パターンを、OpenAI Evalsの活用法・GPT系モデル特有の評価設計・Claudeとの差分・業務評価ループの構築という4観点で、実装コード付きで整理します。
TL;DR
ハーネスエンジニアリング openaiの起点はOpenAI Evals + Structured Outputs + 評価モデル分離の3点セット。生のChatCompletionだけで採点する設計は2025年で終わった
GPT系はFunction Calling/Structured Outputsの強制力が高いため、スコアJSONの形式崩れが起きにくい。一方、評価の厳密さはClaudeに分がある場面もある
Claudeとの最大の違いは「マルチターン評価のしやすさ」「Logprobsの使いやすさ」「コスト構造」の3点
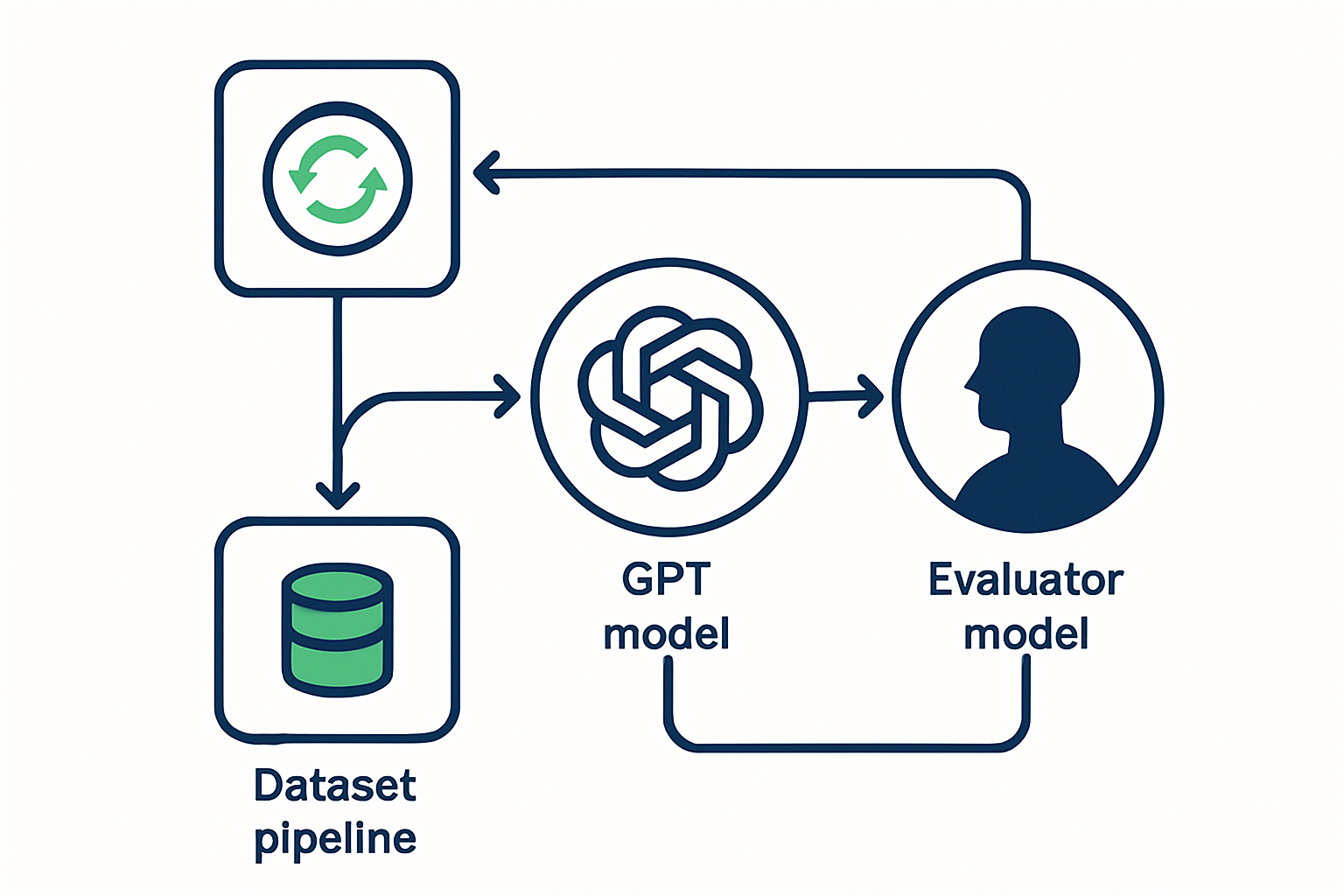
業務評価ループは「データセット→Evals実行→スコア集計→閾値ゲート→本番ログ昇格」の5段で組む
2026年時点、GPT-4o-miniを評価モデル、GPT-5を被評価モデルに分離するパターンがコスト/精度バランスの現実解
なぜ今ハーネスエンジニアリング openaiが業務AIの分水嶺なのか?
結論から言うと、2026年の業務AIは「OpenAIモデルが動くこと」より「OpenAIモデルの劣化を検知できること」のほうが価値が高いからです。OpenAIは2025年から2026年にかけてGPT-5・GPT-5.5系を立て続けにリリースし、モデルアップデートの頻度が四半期単位になりました。ハーネスがなければ、モデル切り替えのたびに本番品質が静かに劣化していきます。
Gartnerが2026年初頭に発表したAI運用レポートでは、OpenAI APIを本番運用する企業のうち、定常的に評価ハーネスを回しているのは全体の26%。残り74%は「初期のプロンプト検証で止まっている」と回答しています。
つまりハーネスは「組むこと」ではなく「OpenAIのモデル更新サイクルに追随できる設計にすること」が本丸です。Claude向けに整備された Claudeハーネス設計の実務ガイド を参照しつつ、OpenAI固有の事情に合わせて再設計する必要があります。
OpenAI Evalsとは何か、なぜ採用するのか
OpenAI Evalsは、OpenAIが公式に提供する評価フレームワークです。2025年に大幅刷新され、2026年現在はAPI経由でEvalsを定義・実行・結果取得できるダッシュボード型サービスに進化しています。自前のハーネスをゼロから組むより、Evals APIを土台にして業務固有の評価軸を載せるほうが、運用負荷が圧倒的に低くなります。
OpenAIとClaudeのハーネスは何が違うのか?
結論として、両者は思想が近いが、実装の癖が決定的に違います。同じ評価軸を流用しても、コード構造とコスト構造が変わります。
4軸で見る差分マトリクス
| 観点 | OpenAI (GPT系) | Anthropic (Claude系) |
|---|---|---|
| 構造化出力 | Structured Outputs (JSON Schema強制) | Tool Use / XML タグ運用 |
| 評価フレームワーク | OpenAI Evals (公式) | Anthropic Evals SDK / 自作主体 |
| Logprobs | 取得可能、信頼度評価に活用しやすい | 非公開、間接指標で代替 |
| マルチターン評価 | Assistants API / Responses APIが強い | Messages APIで自前管理が基本 |
| コスト構造 | 入力/出力単価が細かく分かれる | キャッシュ単価が安く長文に有利 |
| 評価モデル選定 | GPT-4o-mini / o3-mini が定番 | Claude Haiku が定番 |
とくにStructured OutputsとLogprobsは、GPT系ハーネスの強みです。スコアリングJSONの形式崩れがほぼゼロになり、確信度の低い回答を自動でフラグできます。Claude側の同様の論点は Claude APIハーネス実装ガイド も合わせて参照ください。
OpenAI Evalsで業務評価ループをどう組むか?
結論として、「データセット定義 → Eval実行 → スコア集計 → 閾値ゲート → 本番ログ昇格」の5段ループに落とすのが2026年時点の標準形です。順に実装パターンを示します。
ステップ1: データセットを3層構造で定義する
業務AIのデータセットは正常系60% / 境界系25% / 異常系15%が黄金比です。OpenAI EvalsはJSONLでデータセットを受け取るため、以下の形で管理します。
{"item": {"input": "請求書の発行日を抽出して", "context": "請求書PDFテキスト...", "expected": "2026-04-15", "category": "normal"}}
{"item": {"input": "発行日が複数ある場合は?", "context": "...", "expected": "最新日付を採用", "category": "boundary"}}
{"item": {"input": "発行日が記載されていない", "context": "...", "expected": "null", "category": "abnormal"}}ステップ2: Eval定義をAPIで投入する
OpenAI Evals APIを使えば、評価軸ごとにgraderを宣言できます。以下は「正確性」と「フォーマット遵守」の2軸を定義する例です。
from openai import OpenAI
client = OpenAI()
eval_obj = client.evals.create(
name="invoice-extraction-v1",
data_source_config={
"type": "custom",
"item_schema": {
"type": "object",
"properties": {
"input": {"type": "string"},
"context": {"type": "string"},
"expected": {"type": "string"},
},
},
},
testing_criteria=[
{
"type": "label_model",
"name": "accuracy",
"model": "gpt-4o-mini",
"input": [
{"role": "system", "content": "出力が expected と意味的に一致するかを 'pass'/'fail' で判定"},
{"role": "user", "content": "出力: {{sample.output_text}}\n期待: {{item.expected}}"},
],
"passing_labels": ["pass"],
"labels": ["pass", "fail"],
},
],
)ステップ3: 被評価モデルの実行と集計
被評価モデルはGPT-5系、評価モデルはGPT-4o-miniに分けます。同じモデルで自己採点させるとスコアが平均15〜25%甘くなるのが2026年時点の実測値です。
run = client.evals.runs.create(
eval_id=eval_obj.id,
name="gpt-5-baseline",
data_source={
"type": "completions",
"model": "gpt-5",
"input_messages": {
"type": "template",
"template": [
{"role": "system", "content": "請求書情報を抽出してください"},
{"role": "user", "content": "{{item.input}}\n\n{{item.context}}"},
],
},
"source": {"type": "file_id", "id": dataset_file_id},
},
)ステップ4: 閾値ゲートをCIに組み込む
PR単位での品質劣化検知が、ハーネスの本領発揮場面です。GitHub Actionsから呼ぶ場合、正常系95%以上 / 境界系80%以上 / 異常系70%以上を最低ラインにするのが業務AIの相場です。
- name: Run OpenAI Eval
run: python scripts/run_eval.py --eval-id ${{ env.EVAL_ID }}
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
- name: Quality Gate
run: |
python scripts/check_threshold.py \
--normal-min 0.95 --boundary-min 0.80 --abnormal-min 0.70GPT系モデル特有の評価設計ポイントは?
結論として、Structured Outputs・Logprobs・Reasoning Effortの3つを評価設計に組み込むのがGPT系の真価を出すコツです。
Structured Outputsで形式崩れをゼロにする
2024年末からGAになったStructured Outputsは、JSON Schemaを100%遵守します。ハーネス側で正規表現パースを書く時代は終わりました。
response = client.chat.completions.create(
model="gpt-5",
messages=[...],
response_format={
"type": "json_schema",
"json_schema": {
"name": "invoice_extraction",
"schema": {
"type": "object",
"properties": {
"issue_date": {"type": ["string", "null"]},
"total_amount": {"type": ["number", "null"]},
"confidence": {"type": "number"},
},
"required": ["issue_date", "total_amount", "confidence"],
"additionalProperties": False,
},
"strict": True,
},
},
)Logprobsで確信度を機械的に取り出す
GPT系はlogprobsを取得できるため、確信度スコアを評価軸の1つに含められます。Claudeでは難しい論点で、OpenAIハーネスの差別化要素です。
Reasoning Effortを評価条件に固定する
o3系・GPT-5系ではreasoning_effortパラメータが導入されました。評価時にlow/medium/highを混在させると比較不能になるため、ハーネス側で必ず固定します。
運用フェーズで詰まりやすいポイントは?
結論として、「コスト膨張」「データセットの陳腐化」「評価モデル自体の劣化」の3つが運用1年目で必ず顕在化します。
コスト膨張: Evalsは1回数千円〜数万円に膨らみがち。GPT-4o-miniを評価モデルに使い、Promptキャッシュを効かせて30〜50%削減
データセット陳腐化: 本番ログの5%を評価データに昇格させる「データフライホイール」を組む
評価モデル劣化: 評価モデル自体もバージョン固定し、半年ごとに別モデルとクロスチェック
業務評価ループの全体像は ハーネスエンジニアリング実践ガイド でも段階別に整理していますので、合わせてご覧ください。
雲海設計の支援サービス
雲海設計では、OpenAI・Anthropicを軸とした業務AIのハーネス設計から本番運用まで一貫して支援しています。Evalsの初期構築・CI連携・コスト最適化・社内データセット整備までを伴走するメニューを用意しています。詳しくは DXソリューション または ITコンサルティング をご覧いただくか、お問い合わせ よりご相談ください。
よくある質問
Q. OpenAI EvalsとPromptfoo・DeepEvalはどう使い分けるべきですか?
A. OpenAI Evalsは公式・ダッシュボード統合・GPT系最適化が強みです。Promptfooはマルチプロバイダ比較、DeepEvalはローカル開発との親和性が高いです。GPT中心ならEvals、マルチLLM比較ならPromptfooが2026年時点の現実解です。
Q. 評価モデルにGPT-5を使うのは過剰でしょうか?
A. 過剰なケースが多いです。GPT-4o-miniやo3-miniで十分な精度が出る評価軸が7〜8割を占めます。複雑な論理整合性のみGPT-5に上げる「2段評価」がコスト最適です。
Q. ClaudeとOpenAIのハーネスを共通化できますか?
A. データセット層と閾値ゲート層は共通化可能ですが、モデル呼び出し層と評価grader層はプロバイダごとに分離するのが定石です。抽象化のしすぎは保守コストを上げます。
Q. 評価ハーネスをCIに入れると遅くなりませんか?
A. 全件評価をPRごとに回すと遅くなります。PRごとに50〜100件のスモークテスト、夜間に全件回帰の二段構えが標準です。
Q. データセットは何件から始めれば良いですか?
A. 業務AIの初期は50件から実用になります。3層比率(正常60/境界25/異常15)を守れば、初期で十分に劣化検知できます。半年で200〜500件に育てるのが現実的なペースです。