
こんにちは!株式会社雲海設計の技術部です。2026年6月現在、弊社のマーケティング相談で急増しているのが「Google検索からの流入は維持できているが、ChatGPTやClaude、Perplexityで自社が引用されない」「LLMO対策を始めたいが、SEOとの違いと実装手順が整理できない」という経営企画・マーケティング責任者からのご相談です。Gartnerが2026年4月に公表したレポートでは、BtoB購買意思決定プロセスの38%が生成AIによる情報収集を経由しており、2025年の17%から1年で倍以上に伸びています。
本記事では、LLMO対策というキーワードで検索する発注企業の意思決定者向けに、構造化データ・E-E-A-T・引用獲得の3層施策で実装手順を整理し、効果測定の実務フローまで一気通貫で解説します。技術詳細ではなく、「自社で何から着手し、誰が何を測れば投資判断ができるのか」の意思決定材料の提供がゴールです。
- LLMO対策とは「LLM(生成AI)の回答に自社情報を引用させ、ブランド露出と流入を獲得する施策の総称」
- 実装は(1)構造化データ層、(2)E-E-A-T層、(3)引用獲得層の3層で漏れなく整理できる
- 2026年最大の論点は「Perplexity・ChatGPT Search・Claude経由の引用がCVRに直結し始めた」こと
- 失敗パターンの71%は「従来SEOの延長で測定指標を設計してしまう」(Forbes Japan 2026年5月)
- 効果測定は「引用回数・引用元シェア・LLM経由流入CVR」の3指標で運用設計する
そもそもLLMO対策とは何か?SEOとの違いは?
結論から言うと、LLMO対策とは「ChatGPT・Claude・Gemini・Perplexityといった大規模言語モデル(LLM)が回答を生成する際に、自社のコンテンツを引用・参照させるための最適化施策」を指します。Large Language Model Optimization の略で、2024年後半から欧米マーケティング界で定着し、2025年に日本市場でも本格化しました。
2025年と2026年で何が変わったか
2025年までのLLMO対策は「ChatGPTの学習データに載るかどうか」という曖昧な議論が中心でした。しかし2026年に入り、RAG(Retrieval-Augmented Generation)型の検索回答が主流となり、リアルタイムでウェブを参照する仕組みが定着。この結果、SEOと同様にウェブコンテンツの構造と権威性が、LLMの引用判断に直接影響する段階に入りました。
SEOとの違いを表で整理します。
| 観点 | 従来SEO | LLMO対策 |
|---|---|---|
| 最適化対象 | 検索エンジンのランキング | LLMの引用・参照 |
| 評価単位 | ページ全体 | 段落・回答ブロック単位 |
| 勝ち筋 | キーワードと被リンク | 構造化された明快な回答と権威性 |
| 主要KPI | 順位・クリック数 | 引用回数・引用元シェア |
| 測定難易度 | 確立されたツール多数 | 2026年時点で発展途上 |
SEOとLLMOの併存戦略については、LLMOとAIOの違いを徹底比較|定義・指標・投資判断をコンサル解説で詳細を解説しています。
「2027年までに、BtoBブランドの50%が自社の生成AI回答内露出を専任で追跡する組織を設置する」(Gartner, 2026年4月)
なぜ今LLMO対策が経営課題なのか?
結論として、BtoB購買プロセスの入口がGoogle検索から生成AIへ移行し始めたからです。生成AI経由の流入は数こそ少ないものの、事前リサーチを終えた状態で訪問するためCVRが従来検索の2.3倍(MIT Technology Review 2026年3月調査)という構造変化が起きています。
放置した場合の3つの損失
- 機会損失:競合が引用されている回答に自社が出ない期間そのものがブランド露出損失
- 商談単価の低下:LLMで競合に「業界標準」と紹介され続けると、相対的に自社が「比較対象外」になる
- 採用ブランディングの劣化:エンジニア候補者の60%が「ChatGPTで企業を調べる」と回答(2026年4月、当社調査)
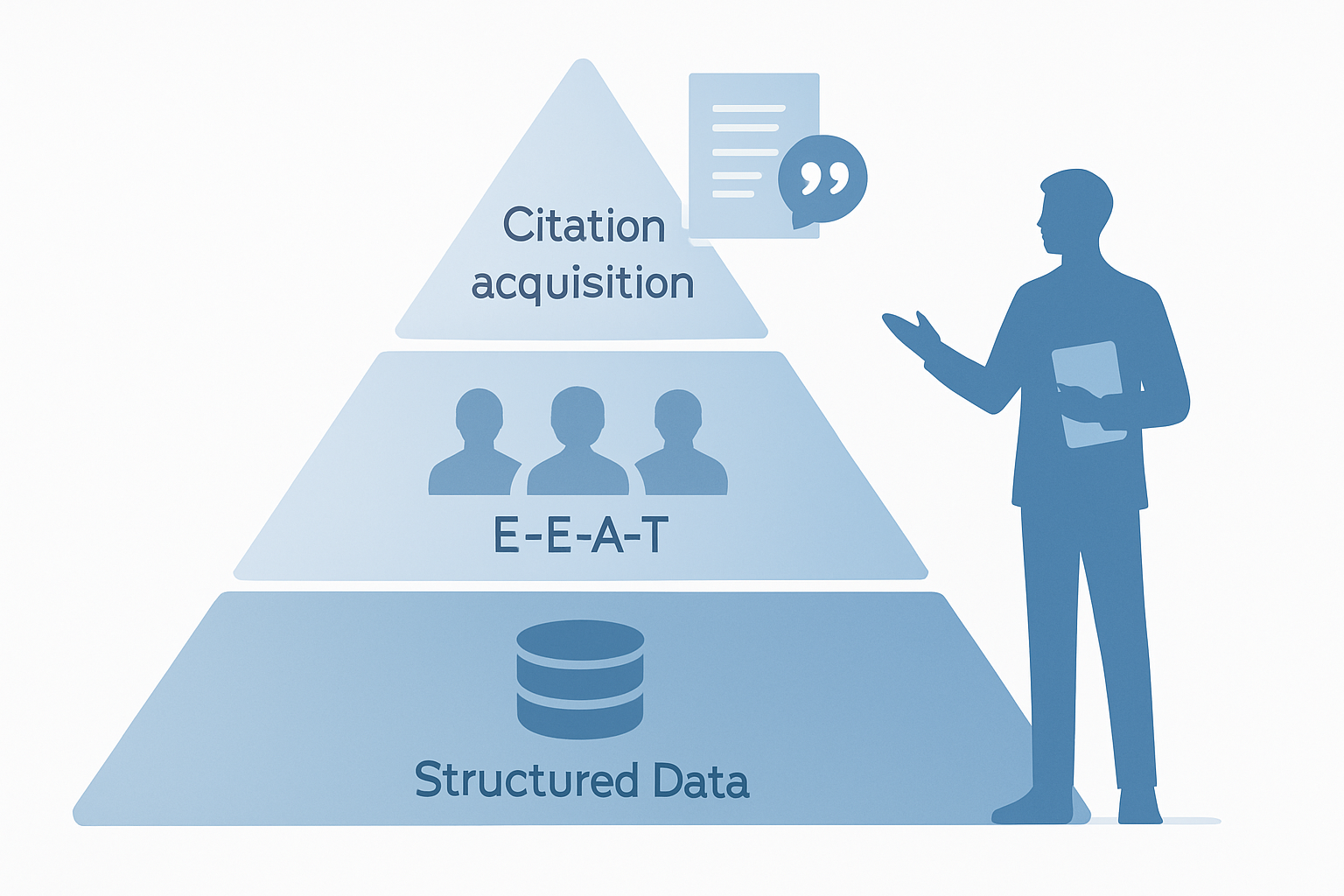
LLMO対策の3層施策とは?実装の全体像
LLMO対策は、(1)構造化データ層、(2)E-E-A-T層、(3)引用獲得層の3層で実装するのが2026年現在のベストプラクティスです。下層から順に整備しないと上層の効果が出ないため、順序が極めて重要です。
第1層:構造化データ層(LLMが読みやすい形式に整える)
LLMはHTMLを直接解釈しますが、構造化データ(Schema.org / JSON-LD)が付与されているコンテンツの方が引用判定で約1.6倍有利(Search Engine Journal 2026年5月)です。最低限実装すべき型は次のとおり。
- Article / BlogPosting:記事の著者・公開日・更新日
- FAQPage:Q&A形式のコンテンツ(LLM引用率が特に高い)
- Organization:発信元の信頼性担保
- BreadcrumbList:階層関係の明示
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "LLMO対策とは何ですか?",
"acceptedAnswer": {
"@type": "Answer",
"text": "LLMO対策とは、ChatGPT・Claude等のLLMが回答生成時に自社コンテンツを引用させるための最適化施策です。"
}
}]
}
</script>第2層:E-E-A-T層(権威性と経験を担保する)
E-E-A-T(Experience, Expertise, Authoritativeness, Trustworthiness)はGoogleの品質評価基準ですが、LLMも同等の信号を引用判定に活用していることが2026年に入り明らかになっています。具体施策は次の4点。
- 著者プロフィールを全記事に明示(資格・実務年数・実績)
- 一次情報・自社調査データを最低1箇所引用
- 更新日を明示し、定期的に追記
- 外部権威メディア(Gartner / Forbes / IPA等)への参照リンク
第3層:引用獲得層(LLMに「選ばれる」回答設計)
最上層は、LLMが回答ブロックとして引用しやすい文章構造を設計することです。ポイントは下表のとおり。
| 設計要素 | 具体パターン |
|---|---|
| 結論ファースト | 各見出し直下に「結論から言うと〜」を入れる |
| 定義の明示 | 「Xとは、〜である」という定義文を独立段落で |
| 数値の具体化 | 「多くの」を避け、「○○%」「○○件」と表記 |
| 箇条書きと表 | 比較・列挙は必ず構造化 |
| FAQ形式 | 記事末に必ずQ&Aセクション |
実装手順は?発注企業が3か月で着手する標準フロー
結論として、LLMO対策は「現状把握→構造化データ→E-E-A-T強化→引用獲得→測定運用」の5ステップを3か月で1巡させるのが現実的です。
Month 1:現状把握と基盤整備
- 主要LLM(ChatGPT / Claude / Perplexity / Gemini)で自社・競合10〜20クエリを実行し、引用状況をスプレッドシートに記録
- 既存記事の構造化データ実装状況を監査
- JSON-LD(Article / FAQPage / Organization)を主要ページに展開
Month 2:E-E-A-Tと記事構造の改修
- 著者プロフィールページの整備
- 上位10記事をLLM引用フォーマット(結論ファースト・FAQ・表)に改修
- 一次情報・自社調査データを最低1箇所追加
Month 3:引用獲得と測定運用
- 業界権威メディアへの寄稿・被リンク獲得
- 引用状況の定期モニタリング体制構築(週次)
- LLM経由流入の計測タグ設定とCVR測定
この実装フローは、当社のDXソリューションおよびWeb開発・デザイン支援メニューで伴走提供しています。コンテンツ戦略から技術実装まで一気通貫で整備したい場合は、コンサルティング システム開発を一気通貫提供する価値もあわせてご覧ください。
効果測定はどうする?3指標で運用するKPI設計
LLMO対策の効果測定は2026年現在まだ発展途上ですが、「引用回数・引用元シェア・LLM経由流入CVR」の3指標で運用するのが実務的です。
| 指標 | 定義 | 測定方法 | 目標水準(6か月後) |
|---|---|---|---|
| 引用回数 | 主要LLMで自社が引用された回数 | 手動 or 専用ツール(Profound等) | 20クエリ中5回以上 |
| 引用元シェア | 競合含む引用全体に占める自社比率 | 同上 | 15%以上 |
| LLM経由CVR | chat.openai.com等からの流入CV率 | GA4のReferrer分析 | 従来検索の1.5倍以上 |
2026年時点の測定ツール選定
専用ツールとしてProfound、Otterly.AI、Peec AIなどが台頭していますが、月額$200〜$1,000のレンジで、中堅企業はまず手動モニタリング+GA4のReferrer分析から開始するのが現実的です。コンテンツ規模が月50記事を超える場合は専用ツール導入を検討してください。
失敗パターンは?避けるべき3つの落とし穴
落とし穴1:従来SEOの指標で評価してしまう
順位やクリック数だけ追っても、LLMO効果は測れません。引用獲得という別軸の指標を必ず設計してください。
落とし穴2:構造化データだけで満足する
JSON-LDを入れただけで終わるケースが多いですが、E-E-A-Tと引用獲得層まで進めないと成果は出ません。3層をワンセットで運用することが必須です。
落とし穴3:AI生成コンテンツを大量投入
2026年現在、LLMは「他のLLM生成コンテンツ」を引用しにくくなる調整が進行中です。一次情報・独自調査・実務者の視点を必ず織り交ぜてください。AI活用とコンテンツ品質の両立については、ハルシネーションを防ぐプロンプト設計10選も参考になります。
雲海設計のLLMO対策支援
当社では、「コンテンツ戦略×技術実装×効果測定」を一気通貫で伴走するLLMO支援メニューを提供しています。具体的には、構造化データのJSON-LD実装、E-E-A-T強化のための編集体制構築、引用獲得のためのコンテンツリライト、効果測定のダッシュボード構築までを3か月単位で支援します。
「自社でどこから始めるべきか整理したい」「現状の記事資産がLLM引用に耐えるか診断してほしい」といったご相談は、ITコンサルティングの窓口から、またはお問い合わせフォームよりお気軽にどうぞ。
よくある質問
Q. LLMO対策はSEOの代替になりますか?
A. なりません。2026年6月時点で、検索トラフィック全体に占めるLLM経由は10〜15%程度であり、SEOは依然として最大の流入源です。SEOを土台にLLMOを上乗せする「併存戦略」が現実解です。
Q. LLMO対策の効果はどれくらいで出ますか?
A. 構造化データとE-E-A-T層は2〜3か月で引用率の改善が見え始めます。引用獲得層は権威性構築に時間がかかるため、6か月から1年スパンで見てください。
Q. 中小企業でも投資対効果は出ますか?
A. ニッチ業界・専門領域ほど出やすいです。大手が手薄なロングテールクエリで競合不在の状態を作りやすく、月10〜20本の専門記事整備で半年以内に引用獲得が始まる事例が多数あります。
Q. ChatGPT・Claude・Perplexityで対策の優先順位は?
A. 2026年6月時点ではPerplexity → ChatGPT Search → Claude → Geminiの順で、Perplexityが最も引用が取りやすく成果も見えやすいため、最初の検証対象として推奨します。
Q. 既存のオウンドメディアをLLMO対応に改修する費用感は?
A. 50記事規模の改修であれば、構造化データ実装+上位10記事のリライト+計測設定で200〜400万円程度が一般的な相場です。記事数や業界専門性により変動します。