
こんにちは!株式会社雲海設計の技術部です。
「ragとは結局なんなのか、社内で説明しても伝わらない」「ベクトルDBやら埋め込みやら用語が多すぎて、発注すべき構成が判断できない」「ChatGPTに社内文書を学習させればいいだけでは?と経営から言われるが、どう違うのか説明できない」——2026年6月現在、ragとは何かに関する発注企業からの相談が、技術部に毎週のように寄せられています。本記事では、RAG(検索拡張生成)の仕組みを発注企業視点で噛み砕き、ベクトル検索・埋め込み・LLM連携の基礎から業務適用パターン、ハルシネーション抑制効果までを実装目線で整理します。
TL;DR
ragとは「Retrieval-Augmented Generation(検索拡張生成)」の略。LLMに社内文書などの外部知識を検索して渡し、その文脈の上で回答を生成させるアーキテクチャ
ファインチューニングが「モデル自体を再学習」するのに対し、RAGは「モデルはそのまま、参照する知識を外付け」する。コスト・更新容易性・監査性の3点で発注企業に有利
構成要素は埋め込みモデル・ベクトルDB・検索層・LLMの4点セット。データ更新は再インデックスのみで済むため、運用コストが軽い
業務適用の本丸は社内FAQ・ナレッジ検索・契約書レビュー・サポート1次回答。2026年の中堅中小では生成AI案件の約6割がRAGベース
ハルシネーション抑制効果は正しく設計すれば誤回答率を3〜5割削減。ただし「検索が外れる」「文脈が長すぎる」設計ミスで逆に悪化するケースもある
ragとは何か?1分で理解する定義
結論から言うと、RAG(Retrieval-Augmented Generation)は「LLMに外部知識を検索して渡し、その文脈の上で回答を生成させる仕組み」です。日本語では「検索拡張生成」と訳されます。2020年にMeta(当時Facebook)のLewisらが論文で提唱した枠組みで、2023年以降の生成AI業務適用ブームで一気に主流化しました。
なぜRAGが必要になったのか
素のLLM(ChatGPTやClaude)には3つの致命的な弱点があります。
知識のカットオフ: 学習時点以降の情報を知らない
社内情報を知らない: 公開Webにない自社固有の情報は答えられない
ハルシネーション: 知らないことをそれっぽく作話する
この3つを、外部の知識ベースを検索して「答えの材料」を渡すことで解消するのがRAGの発想です。LLMを「物知りの人」から「資料を読んで答える人」に変えるイメージが近いと言えます。
ファインチューニングとの違い
RAGとよく対比されるのがファインチューニングです。両者は目的も適用領域も別物で、混同すると投資判断を誤ります。
| 観点 | RAG | ファインチューニング |
|---|---|---|
| 知識の持たせ方 | 外部DBを検索して文脈注入 | モデル自体に学習させる |
| 更新コスト | 再インデックスのみ(低) | 再学習が必要(高) |
| 監査性 | 引用元を提示可能 | 根拠の追跡が困難 |
| 得意領域 | 知識・事実の参照 | 口調・形式の固定 |
| 初期コスト | 低〜中 | 中〜高 |
発注企業視点では、「社内文書を答えさせたい」ならまずRAGが正解です。ファインチューニングは「特定のフォーマットで出力させたい」「専門用語の語彙を覚えさせたい」など、知識ではなく振る舞いを固定したいときの選択肢になります。
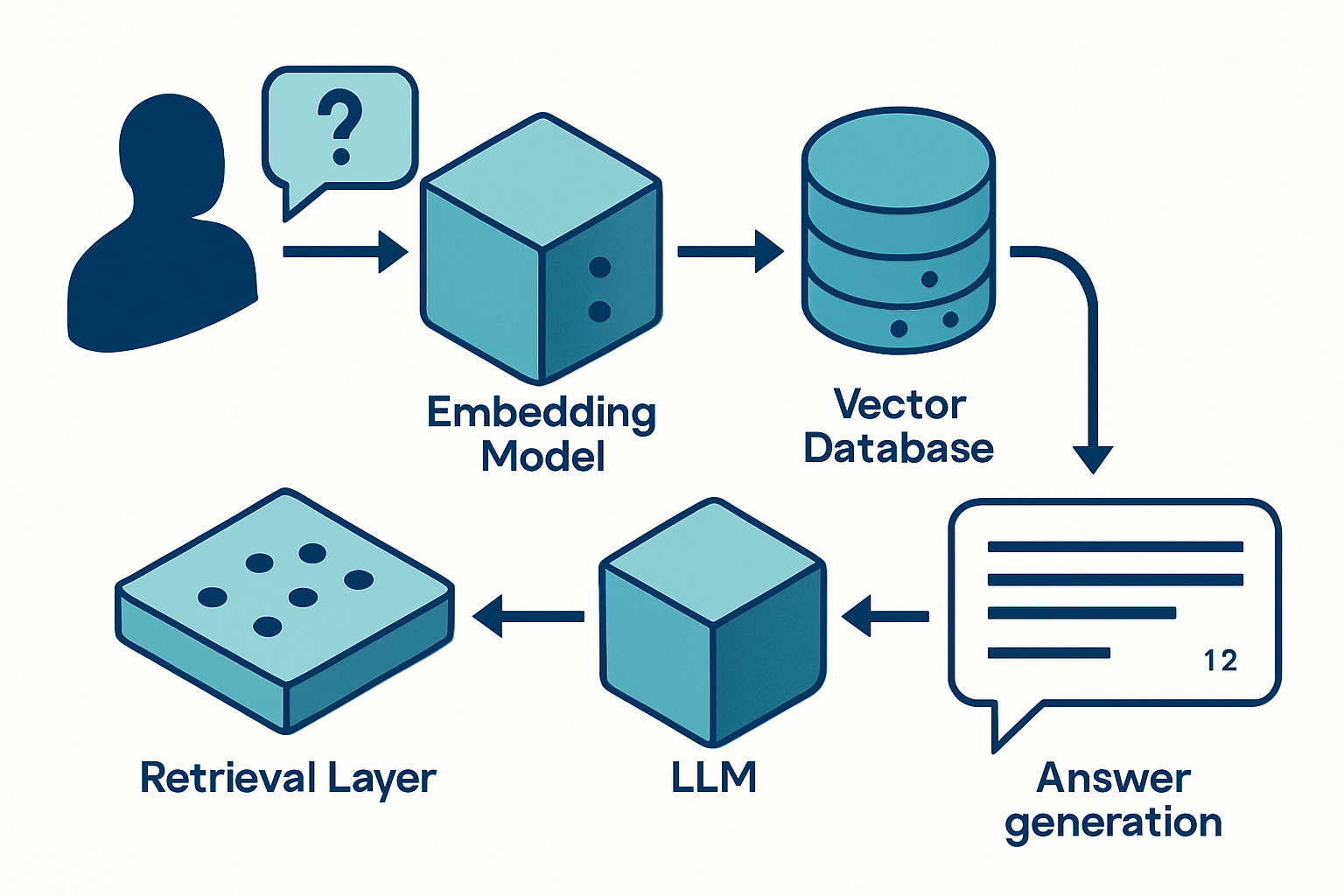
RAGはどう動いているのか?4つの構成要素
結論として、RAGは「埋め込み → ベクトルDB → 検索 → LLM生成」の4段リレーで動きます。それぞれの役割を順に押さえれば、ベンダー提案書を読み解く解像度が一気に上がります。
1. 埋め込みモデル(Embedding)
文章を意味を保持した数値ベクトル(配列)に変換する役割です。たとえば「契約解除の条件」と「解約要件」は文字列としては別物ですが、埋め込み後のベクトルは近い位置に来ます。OpenAIのtext-embedding-3、CohereのEmbed v3、国産のRuriなどが2026年の主要選択肢です。
2. ベクトルDB
埋め込みベクトルを保存し、「意味的に近い文書」を高速検索するためのデータベースです。Pinecone、Weaviate、Qdrant、pgvector(PostgreSQL拡張)などが主流。中堅中小ではコスト面でpgvectorかQdrantが現実解になることが多い領域です。
3. 検索層(Retriever)
ユーザーの質問を埋め込みに変換し、ベクトルDBから関連文書を引いてくる層です。最近はベクトル検索+キーワード検索(BM25)のハイブリッドが標準。さらに上位N件を再ランクするRerankerを挟むことで、検索精度が一段上がります。
4. LLM(生成層)
取得した文書を「文脈(コンテキスト)」としてプロンプトに差し込み、回答を生成します。Claude、GPT、Geminiなどが選択肢。重要なのは「検索結果を引用元として明示させる」プロンプト設計で、これがハルシネーション抑制の生命線になります。
## 最小RAGの擬似コード
query = "契約の解除条件は?"
query_vec = embed(query)
docs = vector_db.search(query_vec, top_k=5)
docs = rerank(query, docs, top_k=3)
prompt = f"""
以下の社内文書のみを根拠に回答してください。
根拠がない場合は『資料に記載がありません』と答えてください。
【参照文書】
{docs}
【質問】
{query}
"""
answer = llm.generate(prompt)
実装の詳細はAIシステム構成図の描き方完全ガイドでRAG・エージェント別に図解しているので、社内説明資料の素材としても参照してください。
RAGはどんな業務に効くのか?適用パターン5選
結論として、RAGは「正解が社内文書のどこかにある」業務で最大の費用対効果を発揮します。2026年6月時点で雲海設計が実装支援してきた案件を類型化すると、以下の5パターンに収束します。
| パターン | 業務領域 | 典型ROI | 難易度 |
|---|---|---|---|
| 社内FAQ自動応答 | 情シス・人事・総務 | 問い合わせ削減40〜60% | 低 |
| ナレッジ検索 | 営業・コンサル・開発 | 探索時間50%短縮 | 低〜中 |
| 契約書・規程レビュー | 法務・購買 | 1次レビュー時間70%短縮 | 中 |
| サポート1次回答 | カスタマーサポート | 有人対応30〜50%削減 | 中 |
| 製品マニュアル検索 | 製造・サービス業 | 現場滞留時間短縮 | 中〜高 |
Gartnerは2026年のGenerative AI Hype Cycleで、RAGを「Slope of Enlightenment(啓発の坂)」に位置づけ、「単独のLLM活用よりも企業適用の主流アーキテクチャになりつつある」と評価しています。
逆にRAGが向かない領域もあります。「正解が文書化されていない」「数値計算が必要」「外部APIを叩く必要がある」業務はRAG単体では解けず、エージェント設計や別アーキテクチャが必要になります。詳しくはAIエージェント比較2026を参照してください。
ハルシネーションは本当に減るのか?
結論として、正しく設計したRAGはハルシネーション(作話)を3〜5割削減できますが、設計を誤ると逆に悪化します。発注前に押さえるべき論点を整理します。
抑制が効く仕組み
RAGは「LLMに『この文書だけを根拠に答えよ』と縛る」構造です。これにより、モデルが知らない情報を作り出す余地が減ります。さらに引用元を提示させれば、ユーザー側でファクトチェックも可能になります。
逆に悪化する3つの失敗パターン
検索が外れる: 関連文書が引けないと、LLMは結局自分の記憶で答えてしまう
文脈が長すぎる: 上位30件など渡しすぎると、LLMが重要部分を見失う
プロンプトの縛りが弱い: 「参考にしてください」程度では参照を無視する
2026年の現場では、「検索精度の評価」と「回答の根拠提示の徹底」が品質を分けます。雲海設計では評価ハーネスを併設するアプローチを標準化しており、その思想はハーネスエンジニアリング実践ガイドとハルシネーションを防ぐプロンプト設計10選で詳述しています。
発注前に押さえるべき設計論点
結論として、RAG案件の成否は「データの前処理」「検索精度」「権限管理」の3点でほぼ決まります。ベンダー提案を見るときの観点としても使えます。
1. データの前処理(チャンキング)
文書をどう分割してベクトルDBに入れるかが品質を左右します。長すぎると検索ノイズが増え、短すぎると文脈が切れます。経験則として1チャンク=300〜800トークン、章単位で意味を保つ分割が安定します。PDFや表組みが多い文書では、構造を保ったまま抽出する前処理ツール選定も重要論点です。
2. 検索精度の評価設計
「検索が外れたらRAGは破綻する」ため、Recall(関連文書の取得率)を業務データで定期的に測定する仕組みが必須です。Hit@5、MRR、nDCGなどの指標で評価ハーネスを組むのが王道。これを怠るとPoC成功・本番失敗の典型パターンに落ちます。
3. 権限管理(Row-level Security)
社内文書には部門・役職別のアクセス権があります。RAGは検索段階で権限フィルタを適用しないと、本来見えない情報が回答に混ざる事故が起きます。これは情報漏洩インシデントの典型で、2025年以降、国内でも複数の報道事例があります。詳細はAIセキュリティ対策実装ガイド2026で実装パターンを整理しています。
graph LR
U[ユーザー質問] --> E[埋め込み変換]
E --> R[検索層+権限フィルタ]
R --> VDB[(ベクトルDB)]
VDB --> RR[Reranker]
RR --> P[プロンプト構築]
P --> L[LLM生成]
L --> A[回答+引用元]2026年のRAG実装、何から着手すべきか
結論として、「最小スコープの社内FAQ or ナレッジ検索」からPoCを始め、評価ハーネスで品質を可視化しながら段階拡大するのが王道です。フルスコープで一気に作ろうとすると、データ整備の時点で頓挫します。
対象業務を1つに絞る: 全社展開ではなく、まず情シスFAQなど明確な領域
正解データを100問用意する: 評価がないPoCはPoCではない
pgvector or Qdrantで最小構成: いきなり高機能DBは不要
権限とログを最初から設計: 後付けは事故のもと
3ヶ月で本番投入判断: PoCが半年超えたら方針再考
雲海設計では、RAGのアーキテクチャ設計からPoC、本番運用までを一気通貫で支援しています。社内データの棚卸しから始めたい場合はDXソリューション、設計と発注の判断軸を整理したい場合はITコンサルティングをご覧ください。具体的な構想ベースの相談はお問い合わせから承ります。
よくある質問
Q. ragとファインチューニング、結局どちらを選ぶべき?
A. 「社内文書の知識を答えさせたい」ならRAG、「特定の口調や出力形式を固定したい」ならファインチューニングです。2026年の業務適用案件の約8割はRAGで足り、ファインチューニングは特殊用途に限定されます。
Q. ChatGPTに社内文書をアップロードするのとRAGは違うの?
A. 違います。ChatGPTのファイルアップロードは内部的に簡易RAGを使っていますが、ファイル数・更新頻度・権限管理・監査ログの観点で業務適用には不十分です。本格運用では自社環境にRAG基盤を構築するのが標準です。
Q. RAGの構築コスト相場は?
A. 中堅中小向けのPoCで200〜500万円、本番運用基盤で500〜1500万円が2026年の相場感です。データ量・権限設計の複雑度・対象業務数で変動します。スコープを絞れば100万円台のPoCも可能です。
Q. ベクトルDBは何を選べばいい?
A. 小〜中規模ならpgvector(既存PostgreSQLに同居)が最も低コスト、専用DBが必要ならQdrantかWeaviateが扱いやすい選択肢です。Pineconeはマネージドで楽ですが、データ主権を社外に出す判断が必要になります。
Q. RAGを入れればハルシネーションはゼロになる?
A. ゼロにはなりません。3〜5割の削減が現実的な数字で、残りは引用元の提示・ガードレール設計・人間レビューの組み合わせで管理します。「ゼロにする」前提の業務設計はリスクが高すぎます。